

Have you ever wondered how bg companies like Netflix or Amazon stay so smart? They don’t just guess what you want to watch or buy. They use a massive amount of information. But there is a catch: that information is usually a mess! It lives in different places like spreadsheets, website logs, and payment apps. To make sense of it, they need a special “digital plumbing” system.
This system is called an etl pipeline. It is the secret ingredient that turns raw, confusing numbers into clear insights. In this guide, we will break down the etl pipeline meaning in the simplest way possible. We will look at what is an etl pipeline, how you can build one using etl pipeline python code, and which etl pipeline tools are winning in 2026. Whether you are a student or a business owner, you will leave here knowing exactly how data moves from point A to point B.
What is an ETL Pipeline? The Simple Definition
To understand what is etl pipeline, think of it as a delivery truck for data. But it is not just any truck; it is a mobile kitchen! As the truck picks up raw ingredients (data), it cleans them, chops them, and cooks them. By the time the truck reaches the restaurant (the data warehouse), the meal is ready to be served to the customers (the business analysts).
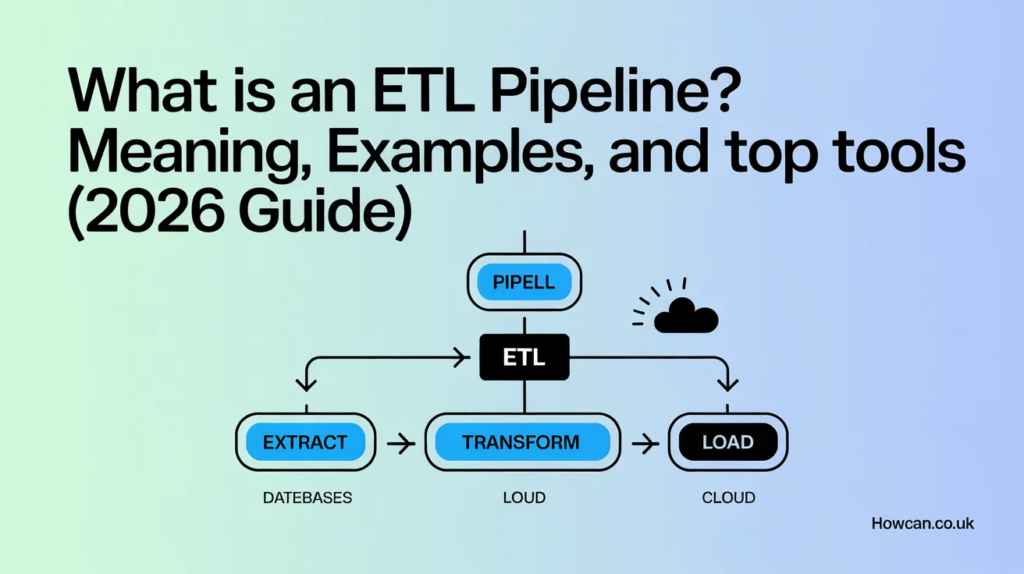
The etl pipeline meaning comes from its three main steps: Extract, Transform, and Load. First, it pulls data from sources like a CRM or a SQL database. Next, it changes that data into a format that is easy to read. Finally, it drops that clean data into a safe storage spot. Without this process, data would be like a library where all the books are thrown on the floor in random piles. An etl pipeline puts every book on the right shelf so you can find it.
How Does an ETL Pipeline Work? The Three Steps
The “Extract” phase is where the journey begins. The pipeline reaches out to various systems to grab raw data. This could be customer names from a website or sales numbers from a cash register. It’s like gathering all your mail from different mailboxes. At this stage, the data is often “dirty” and full of mistakes.
The “Transform” phase is the most important part. This is where the magic happens! The system cleans up the data. It removes duplicates, fixes typos, and makes sure all the dates look the same. For example, if one system says “01/02/26” and another says “Feb 1, 2026,” the transformation step fixes them to match. This ensures that the information is high-quality and trustworthy for the boss to read.
Why Every Modern Business Needs a Data Pipeline
In 2026, data is more valuable than oil. But raw data is hard to use. A well-built etl pipeline saves a company hundreds of hours of manual work. Instead of a human copying and pasting numbers into an Excel sheet, the pipeline does it automatically every night while everyone is sleeping. This means the team always has fresh information when they start work in the morning.
Also, having an etl pipeline helps with “Data Governance.” This is a fancy way of saying it keeps data safe and organized. It allows companies to see exactly where their information came from and who changed it. This is very important for staying following the law, especially in areas like banking or healthcare where privacy is a top priority.
A Real-World ETL Pipeline Example
Let’s look at a common etl pipeline example from an online clothing store. The store sells shirts on its website, but it also tracks what people say about them on social media. The etl pipeline extracts sales data from the store’s database and “likes” from Instagram.
During the transformation step, it joins these two lists together. It realizes that “User_123” who liked a photo is the same person who bought a blue shirt. Finally, it loads this combined info into a dashboard. Now, the store manager can see that Instagram ads are actually helping sell shirts! This is how a simple etl pipeline helps a business grow by connecting the dots.
Top ETL Pipeline Tools to Use in 2026
Choosing the right etl pipeline tools depends on how much data you have and how much money you want to spend. In 2026, AI-powered tools are the big winners because they can fix data errors automatically. Some tools are “no-code,” meaning you just drag and drop boxes to move data. Others require a bit of programming knowledge but offer more control.
- Fivetran: Great for companies that want everything to work automatically without writing code.
- Apache Airflow: An open-source favorite for engineers who like to schedule complex tasks.
- dbt (data build tool): Perfect for the “Transform” part of the pipeline.
- Azure Data Factory: A top choice for businesses already using Microsoft products.
Why Data Scientists Love ETL Pipeline Python
Python is the king of data languages. Building an etl pipeline python style is very popular because it is flexible and free. Python has special libraries like Pandas and Dask that can handle millions of rows of data with just a few lines of code. It feels like having a Swiss Army knife for your data.
When you use etl pipeline python scripts, you can customize every single step. You can write a script that sends you a text message if the pipeline fails, or one that automatically creates a chart for your weekly meeting. Most modern data engineers start their careers by learning how to write these Python scripts because they work so well with cloud platforms like AWS and Google Cloud.

ETL vs. ELT: What Is the Difference
You might also hear about something called “ELT.” While it sounds the same, the order is different. In ETL, you transform the data before it gets to the warehouse. In ELT, you load the raw data first and then transform it later. This is becoming more common because modern cloud warehouses are incredibly fast and can handle the heavy lifting of cleaning data.
ETL is usually better if you have a lot of sensitive information that needs to be cleaned for privacy before it is stored. ELT is often faster for massive amounts of “Big Data” where you want to save every single detail immediately. Both are types of pipelines, but the “when” and “where” of the cleaning step is what sets them apart.
Common Challenges in Building a Pipeline
Building a pipeline isn’t always easy. Sometimes the data source changes its format without telling you. This is called “Schema Drift,” and it can break your pipeline. Imagine if your delivery truck showed up to a warehouse, but the loading dock had been moved to the roof! You wouldn’t be able to deliver the goods.
Another challenge is “Data Quality.” If the source data is really bad, even the best pipeline might struggle to fix it. This is why it is important to have “Data Validation” steps. These are like little checkpoints in the pipeline that test the data. If something looks wrong—like a price being a negative number—the pipeline stops and alerts a human to fix the issue.
The Future of ETL: AI and Real-Time Data
In the past, pipelines only ran once a day (usually at midnight). But in 2026, businesses want “Real-Time” data. They want to see a sale the second it happens. New etl pipeline tools are now using “Streaming” technology to move data instantly. This allows for things like instant fraud detection in banking.
AI is also changing the game. Modern pipelines can now “self-heal.” If an AI detects that a data format has changed, it can try to rewrite the transformation code itself to keep the data flowing. This makes the job of a data engineer much easier and ensures that the business never loses its “Single Source of Truth.”

Conclusion
An etl pipeline is much more than just a technical process. It is the backbone of modern intelligence. By understanding the etl pipeline meaning and seeing how an etl pipeline example works in real life, you can see why this technology is so vital. Whether you use etl pipeline tools or write your own etl pipeline python code, the goal is the same: turning messy data into clear, actionable power.
Are you ready to stop drowning in messy spreadsheets and start using your data like a pro? There has never been a better time to explore these tools and build your first pipeline!
FAQs
1. Is an ETL pipeline the same as a data pipeline?
Not exactly. A data pipeline is a general term for any system that moves data. An ETL pipeline is a specific type of data pipeline that must include the “Transform” step to clean or change the data.
2. Can I build an ETL pipeline for free?
Yes! Using etl pipeline python libraries like Pandas and open-source tools like Apache Airflow, you can build a powerful system without paying for expensive software.
3. How long does it take to run an ETL process?
It depends on the amount of data. Small pipelines might take seconds, while massive enterprise pipelines handling billions of records might take several hours to finish.
4. What is the most important part of ETL?
Most experts say the “Transformation” phase is the most critical. This is where you ensure the data is accurate and clean. If you load bad data, you will get bad results (Garbage In, Garbage Out).
5. Do I need to be a coder to use ETL tools?
Not anymore! Many modern etl pipeline tools like Fivetran or Skyvia are “no-code.” This means you can set them up using a simple website interface without writing a single line of code.
6. Why is it called a “pipeline”?
It is called a pipeline because data flows through it in one direction, just like water through a pipe. It starts at the source and ends at the destination, passing through various “filters” (transformations) along the way.

{kind=link}